MDMPro:smpl motion2motion diffusion model
这是本科期间做的一个科研项目,要解决的问题是:在乒乓球对打场景下,给定对手的 SMPL 动作序列,如何预测并生成己方合理的动作响应。这种数据驱动类的work包含了数字人动捕的几个核心pipe——数据从哪里来、动作序列用什么表示、以及如何在条件生成中balance好语义准确性与多样性之间的张力。
What is SMPL
SMPL[1](Skinned Multi-Person Linear Model)是目前参数化人体建模中应用最广泛的框架之一。它用形状参数
乒乓球对打场景对这个问题提出了一个结构性的困难:击球动作的语义核心不在于躯干和下肢的大幅运动,而在于手腕与指关节的精细控制——拍面角度、击球时机、旋转施力方式,都编码在这几个关节的运动轨迹里。然而在标准 SMPL 表示中,所有 52 个关节在特征空间里地位平等。当对动作序列做降维、投影或归一化时,手部的十余个关节会被躯干、大腿等大关节的运动方差所主导,其贡献在表示空间中被系统性地稀释。对一个以手部运动为核心的任务来说,这不是一个可以被忽视的设计缺陷。
我们的工作由三部分组成:构建乒乓球对打 SMPL 数据集、设计一种可以放大手部关节表示权重的动作序列表示形式、以及在此基础上修改 Motion Diffusion Model 实现条件动作生成。
数据集构建:From Monocular to Multi-view capture
乒乓球 SMPL 动作数据集不存在现成的公开版本,整个数据流程需要从头搭建。这也是作为数据驱动的该工作最大的贡献点之一。
第一阶段是单视角数据的爬取与处理。我们从公开渠道收集了大量乒乓球对打视频,使用 pyMAFX[2] 对每帧图像进行单视角 SMPL 姿态估计,得到初步的双方动作序列。但单视角重建本身存在根本性的深度歧义——仅凭一个视角无法可靠地恢复人体在三维空间中的全局位移,而相机外参的估计误差也会累积到关节姿态上。为此,我们在 pyMAFX 的输出基础上引入了 PnP(Perspective-n-Point)位姿优化:利用检测到的人体关键点与已知相机内参,通过 PnP 求解人体根节点的全局位姿,并以此为约束对单帧估计结果做后处理修正,显著提升了动作序列的空间一致性。
第二阶段是实地多视角采集。我们架设了 9 台工业相机,通过硬件触发信号实现帧级同步,对实际乒乓球对打场景进行多视角拍摄。在此基础上使用多视角数字人重建算法对双方的 SMPL 姿态进行联合优化估计。多视角约束从根本上解决了深度歧义问题,人体全局位移和关节旋转的估计精度均有质的提升。
第三阶段是数据配对与标注。将双方的动作序列按时间戳对齐,构建出「对手动作序列
Emphasis Projection:让手部关节更好的被"看见"
原始 SMPL 动作序列是一个高维时序张量:
我们设计了一种 Emphasis Projection:在将动作序列投影到低维表示空间的同时,主动放大手部关节对应维度的贡献,同时通过归一化因子确保投影的整体统计特性不发生漂移。
设展平后的动作序列特征向量为
分母中的归一化项

扩散模型在投影空间
推理时从高斯噪声出发,经过 reverse diffusion 采样得到
生成模型:修改 Motion Diffusion Model
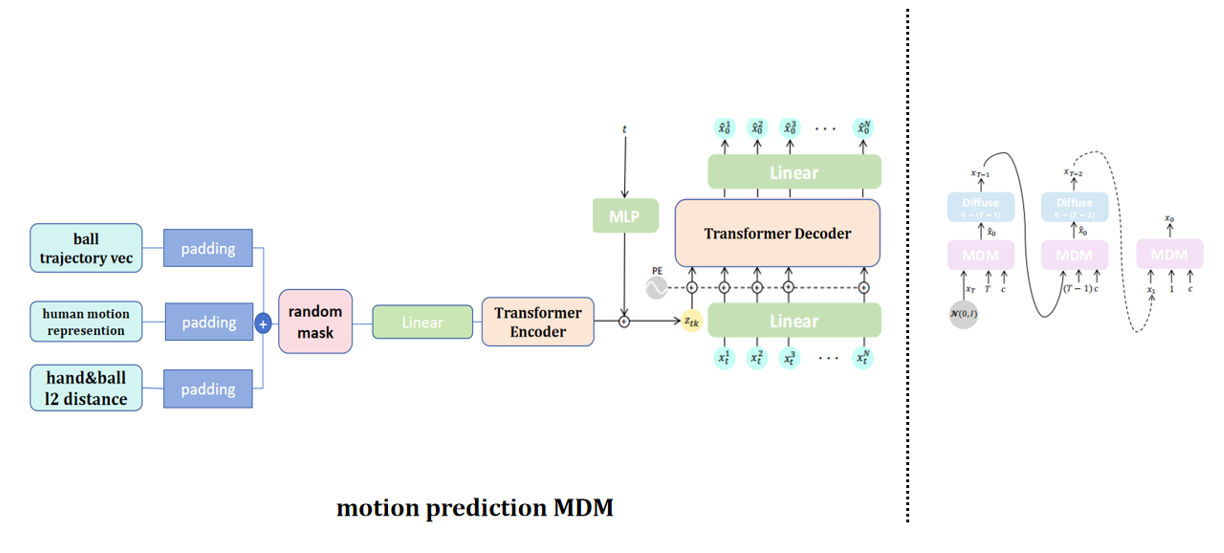
生成模型以 Motion Diffusion Model(MDM) 为基础框架。MDM[4] 是一个 Transformer-based 的扩散模型,原始设计以文本或动作类别作为条件,在关节旋转序列空间上执行扩散过程。在我们的任务中,条件信号从离散标签变成了一段时序连续的对手动作序列,需要重新设计条件注入机制。
我们将对手动作序列经过与己方相同的 Emphasis Projection 处理后,得到条件表示
推理时使用 DDIM 加速采样,在保持生成质量的同时将采样步数降低到可接受的范围。
结果
最终生成的效果如下。在给定对手连续击球动作序列的条件下,模型生成的己方响应动作在时序节奏和手部姿态上均能保持合理的语义一致性,同时在非关键帧区间保有一定的动作多样性——这正是条件动作生成任务所追求的两个核心性质之间的平衡。
参考文献
Loper, Matthew, et al. “SMPL: A skinned multi-person linear model.” Seminal Graphics Papers: Pushing the Boundaries, Volume 2. 2023. 851-866. ↩︎
Zhang, Hongwen, et al. “Pymaf-x: Towards well-aligned full-body model regression from monocular images.” IEEE Transactions on Pattern Analysis and Machine Intelligence 45.10 (2023): 12287-12303. ↩︎
Ho, Jonathan, Ajay Jain, and Pieter Abbeel. “Denoising diffusion probabilistic models.” Advances in neural information processing systems 33 (2020): 6840-6851. ↩︎
Tevet, Guy, et al. “Human motion diffusion model.” arXiv preprint arXiv:2209.14916 (2022). ↩︎