DreamFragment——3D-Instance aware的多物体 3D 场景生成
这是我研一期间在实验室做的工作 DreamFragment,在这篇博客中,我先尽量用介绍paper的视角介绍一下我这篇工作都干了什么。而下一篇博客我将和大家介绍一下这篇工作幕后的design space和想法,我认为可能更加有趣和给人启发。
3D多物体生成的key challenge 是:如何从文字描述中生成多个物体相互交互的复杂 3D 场景,并且每个物体可以被单独分离出来。我们试想一下,当前的Trellis[1]也好还是GaussianDreamer[2]也好,首先focus在单物体生成。也就是说,当此类方法处理包含多个物体相互交互的复杂 3D 场景时,会将多个物体”揉“在一起,以单个物体的方式生成。当下游任务诸如3D Editing想要单独修改某个物体时,不难发现是有一定工程量且并非容易的:首先需要通过后处理的方法,使用3D SegmentAnything将场景中的物体分开;其次,分开后的物体只要在原场景中有相互接触关系,就会出现 高斯空洞, 如图所示。
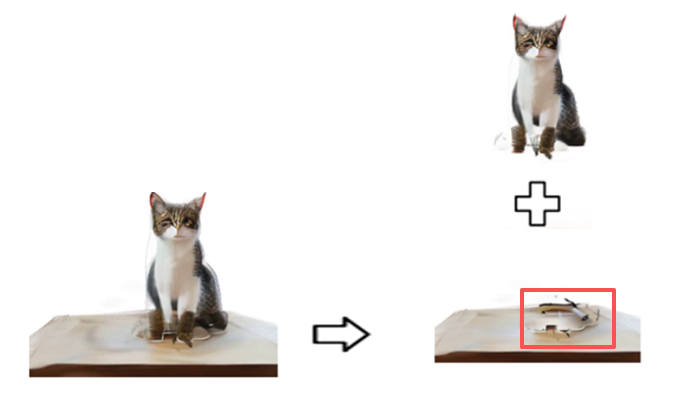
所以,当物体之间有真实的接触和遮挡关系——比如「一只猫把前爪搭在桌子上」「宇航员穿着游泳圈」——sota的方法(Hunyuan3D那些feed-forward方法没出来前) 就会系统性地失败。至此,我们提出了一个疑问:How can we facilitate fine-grained instance relation modeling to generate scenes with complex interactions? 我们的key insight系统性的回答了该问题–多物体场景生成中,实例关系建模应该贯穿整个生成流程,而不仅仅是一个后处理步骤,我们始终通过3D-Aware的策略贯穿初始化和生成的全流程。这样的解决方案不仅在相同基座模型下更加高效,省去了繁琐的后处理,而且生成场景中的物体天然解耦,非常有利于下游3D editing等任务。
问题的引出
3D 内容生成近年来随着 NeRF、3D Gaussian Splatting(3DGS)以及扩散模型的快速发展取得了长足进步。但单物体生成和多物体场景生成之间有一条实质性的鸿沟——后者不仅要求每个物体自身具备完整的几何和外观,还要求物体之间的空间关系和接触面在语义上是准确的。
当前做法在处理这类场景时,有两个地方会系统性地出问题。第一是初始化阶段:大多数方法独立地初始化每个物体的 3D 结构,然后再尝试将它们拼合在一起。这种方式天然丢失了物体之间的语义依赖——猫的爪子和桌面是什么关系、游泳圈和宇航员的腰部如何贴合,在独立初始化的框架下根本无法被正确建立。第二是布局表示:现有方法通常用 LLM 生成 3D 包围盒或物体中心坐标来描述物体的空间位置,这种粗粒度表示对于简单的并排场景勉强够用,但对于需要精细接触面建模的复杂场景来说远远不够。
DreamFragment 认为这两个问题的根源是一致的:整个生成流程对实例间关系的建模过于粗糙。我们的回答是在初始化、布局表示、优化三个环节分别引入实例感知(instance-aware)机制。
相关工作
在 compositional multi-object 3D generation 这个方向上,几个代表性工作各自选取了不同的技术路线。GraphDreamer[3] 用场景图来建模物体间关系,把场景描述分解成图结构,再从图的边生成 sub-prompt 来指导每对物体之间的优化;DreamDissector[4] 把单个 NeRF 里的多个物体用轻量级的 Neural Category Field(NeCF)解耦成独立的 sub-NeRF;GALA3D[5] 用 3D Gaussians 作为表示,通过 LLM 生成每个实例的包围盒,再分别用实例级和场景级扩散先验进行优化。
这些方法的共同局限在于:初始化阶段对实例间的语义依赖是 agnostic 的,布局表示的粒度不足以捕捉精细的空间配置,而优化阶段的逐对处理或顺序优化也会丢失全局的上下文信息。
在优化范式上,Score Distillation Sampling(SDS,DreamFusion[6] 提出)是这类方法的基础,但其模式寻找的本质会导致过度饱和和过度平滑的外观。ProlificDreamer[7] 提出的 Variational Score Distillation(VSD)和 LucidDreamer[8] 提出的 Interval Score Matching(ISM)在单物体生成上显著改善了这一问题。DreamFragment 在多物体场景优化上采用 ISM 作为基础优化目标,并在此基础上引入实例感知机制。
另一个关键的 inspiration 来自 LayerDiffuse[9] ——这篇工作通过 attention sharing 在 2D 生成中建模多个图层之间的细粒度交互关系。我们把这个思路扩展到 3D:在布局优化阶段,用一个多图层扩散模型同时处理「当前实例」「上下文(其他物体)」「完整场景」三个 latent,从而实现实例级别的感知。
DreamFragment 的方法
整个流程遵循「初始化 → 两阶段优化」的框架,3D Gaussian Splatting 作为 3D 表示的骨干。
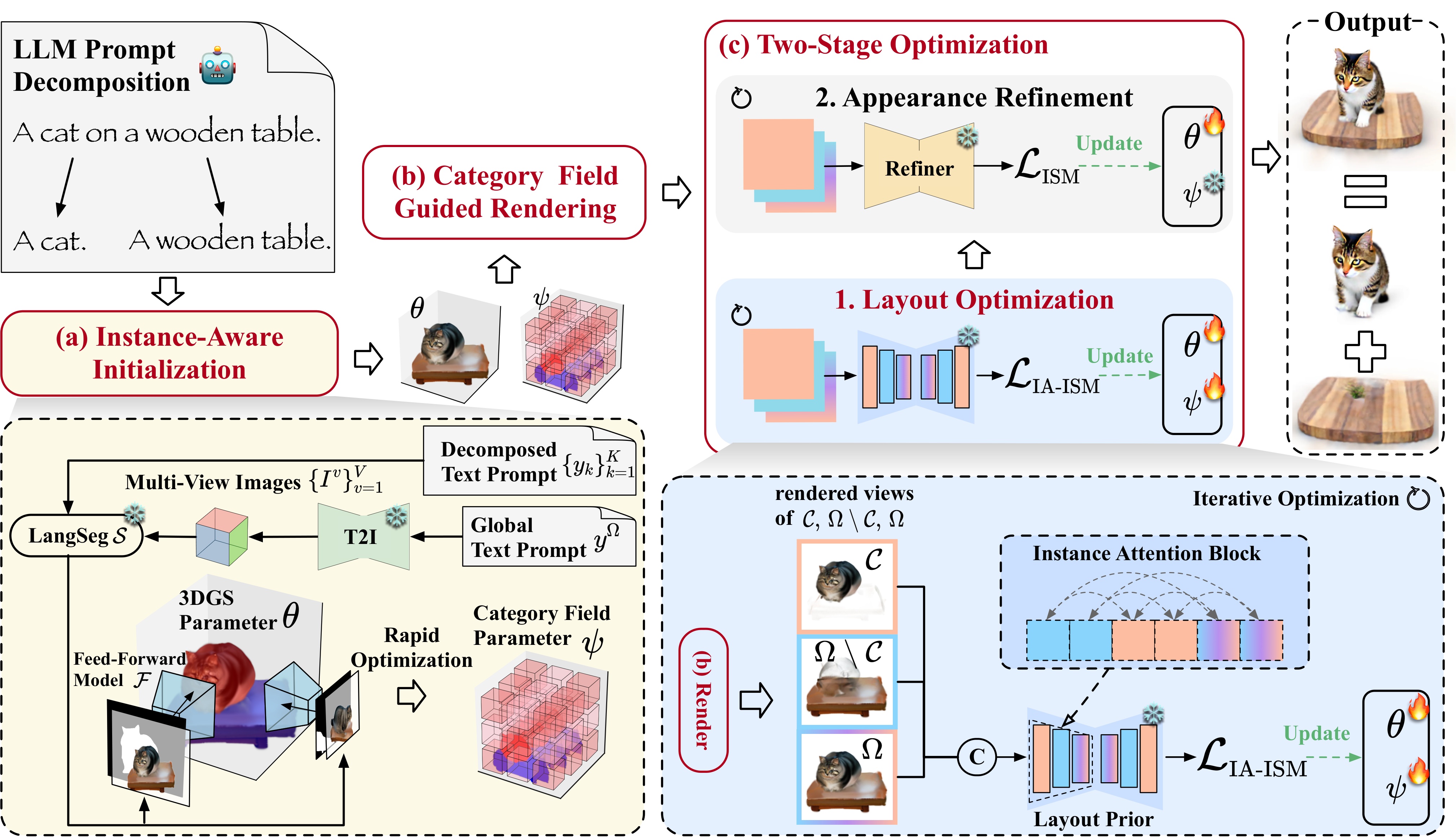
实例感知初始化
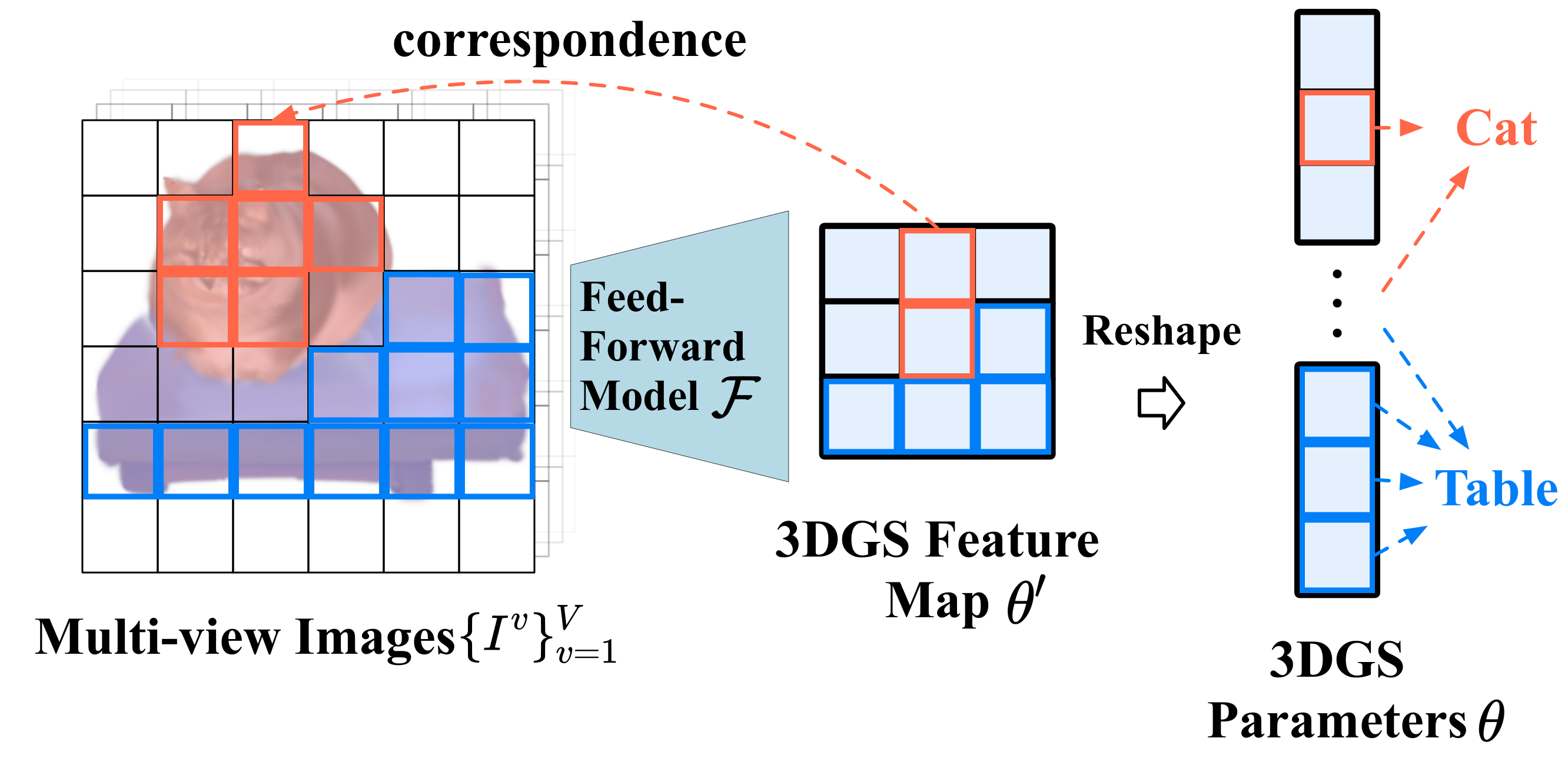
给定场景的全局文字描述
然后,我们用 LGM(一个 feed-forward 3D 重建模型)把这些多视角图像转化为初始的 3D Gaussians
问题在于:如何把这
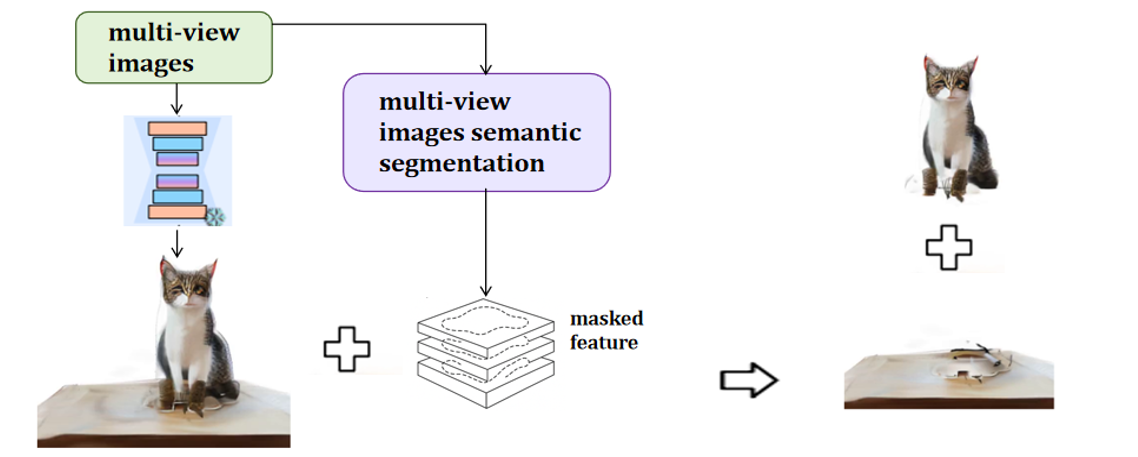
这个设计的优雅之处在于:联合生成保留了语义依赖,LGM 的空间对应关系实现了实例分离,两者各司其职而不冲突。
Category Field 引导的渲染
3D Gaussian Splatting 的一个固有问题是:点云式的无结构表示没有清晰的物体边界。两个物体的 Gaussians 在空间上会相互渗透,导致渲染时出现物体互相嵌入的 artifact。之前的方法要么用包围盒(GALA3D)要么用变换矩阵(Epstein et al.)来区分物体,这些方法的粒度都不足以建模精细的接触面。
我们把 DreamDissector 中用于 NeRF 的 Neural Category Field(NeCF)扩展到 3D Gaussians 上。NeCF 是一个轻量级的 MLP(用 multi-resolution hash grid 参数化),它接受空间坐标
对于 NeRF,NeCF 把密度场分解到
引入 category field 后,第
这个修改让每个 Gaussian 的渲染贡献按其空间位置动态地分配给各实例,而不是硬性地属于某一个物体。Category field 从 IAI 的分配结果出发,通过最小化交叉熵损失快速初始化,整个过程在 10 秒内完成。

此外,我们设计了一个 Boundary-Aware Pruning 策略:追踪每个 Gaussian 在训练过程中的历史类别状态,如果当前预测类别与历史类别不一致,则在下一轮迭代中将其剪除。这个简单的策略有效地消除了处于物体边界处容易发生类别翻转的 Gaussians,使物体边界更加干净。
两阶段优化
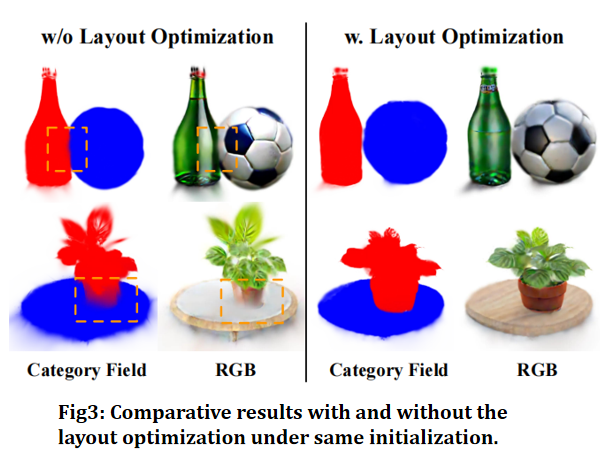
第一阶段:Layout Optimization。 初始化得到的每个实例 Gaussians 往往几何破碎、布局错位。我们用一个 instance-context-aware 的扩散先验来修复几何的同时优化精细布局。具体地,我们采用 LayerDiffuse(
布局优化的梯度(Instance-Aware ISM,IA-ISM)为:
其中
第二阶段:Appearance Refinement。 受制于 LayerDiffuse 自身的模型容量,第一阶段的结果往往缺乏纹理细节。第二阶段冻结 category field 参数
两阶段的分工逻辑:第一阶段建立正确的空间关系和几何结构,第二阶段在固定布局的前提下提升视觉质量,二者目标不同、互不干扰。
实验
定量结果。 我们用 CLIP Text-Image Similarity Score 评估生成质量,分别在完整场景和分离后的单个实例两个维度上进行衡量。在全场景评估上,DreamFragment 在 ViT-B/16、ViT-B/32、ViT-L/14 三个 CLIP backbone 下分别达到 0.335、0.336、0.290,显著优于最强基线 GraphDreamer(0.326、0.319、0.274);在单实例评估上,DreamFragment 同样超过 GALA3D 和 GraphDreamer,达到 0.303、0.299、0.260。
| 方法 | ViT-B/16 ↑ | ViT-B/32 ↑ | ViT-L/14 ↑ |
|---|---|---|---|
| DreamFusion[6:1] | 0.324 | 0.310 | 0.272 |
| ProlificDreamer[7:1] | 0.319 | 0.306 | 0.274 |
| GaussianDreamer[2:1] | 0.315 | 0.310 | 0.271 |
| LucidDreamer[8:1] | 0.309 | 0.300 | 0.252 |
| GraphDreamer[3:1] | 0.326 | 0.319 | 0.274 |
| GALA3D[5:1] | 0.310 | 0.282 | 0.279 |
| DreamFragment(Ours) | 0.335 | 0.336 | 0.290 |

定性结果。 对于「宇航员穿着游泳圈」这类具有精细接触关系的场景,DreamFusion[6:2] / ProlificDreamer[7:2] 要么无法正确生成指定物体,要么位置关系明显错误;GaussianDreamer[2:2] / LucidDreamer[8:2] 则直接无法分离出独立物体;GALA3D[5:2] 和 GraphDreamer[3:2] 虽然能生成多物体,但空间准确性和 prompt 完整性都有明显缺失。DreamFragment 在所有测试场景下均能生成语义准确、空间合理、可独立分离的多物体 3D 场景。

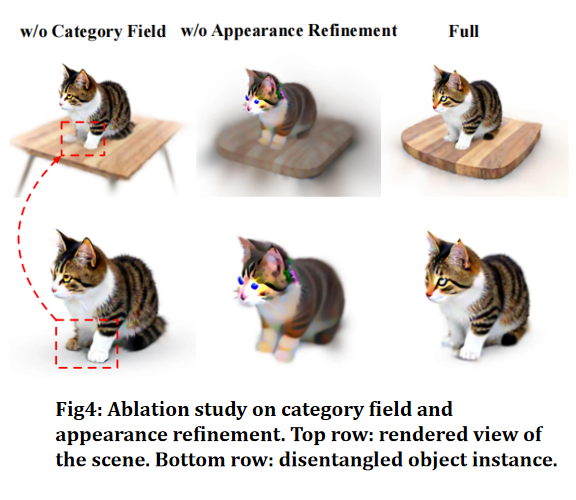
消融实验。 四个核心组件均做了消融:
去掉 Instance-Aware Initialization 后(用 GaussianDreamer 的初始化方式替换),各物体之间的相对位置和接触关系质量明显下降,说明联合初始化对语义依赖的捕获至关重要。

去掉 Layout Optimization 后,仅靠 appearance refinement 优化的结果出现形状变形和实例边界模糊的问题——这说明第一阶段的布局优化不能被跳过,它建立的几何结构是第二阶段的前提。
去掉 Category Field 后(将每个 Gaussian 硬性分配给固定实例),会出现物体相互嵌入的 clipping artifact,比如猫的前爪错误地嵌入桌面。Appearance Refinement 的作用则主要体现在纹理细节的提升上,缺少这一阶段的结果几何正确但外观粗糙。
整个系统运行在单张 RTX 4090 上,显存占用约 22GB。
总结
DreamFragment 的核心贡献是把 instance-aware 机制系统性地嵌入多物体 3D 生成的整个流程——初始化阶段通过联合场景生成 + LGM 空间对应实现语义感知的实例分离;布局表示阶段通过 category field 替代粗粒度包围盒实现精细边界建模;优化阶段通过 LayerDiffuse[9:1] 作为 instance-context-aware 先验捕获物体之间的精细交互。我们的结果从定性和定量均超过的当时的sota的方案。
下篇博客我们来聊聊 DreamFragment 的inspiration和实际的设想动机。
参考文献
Xiang, Jianfeng, et al. “Structured 3d latents for scalable and versatile 3d generation.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2025. ↩︎
Yi, Taoran, et al. “Gaussiandreamer: Fast generation from text to 3d gaussians by bridging 2d and 3d diffusion models.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2024. ↩︎ ↩︎ ↩︎
Gao, Gege, et al. “Graphdreamer: Compositional 3d scene synthesis from scene graphs.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024. ↩︎ ↩︎ ↩︎
Yan, Zizheng, et al. “Dreamdissector: Learning disentangled text-to-3d generation from 2d diffusion priors.” European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2024. ↩︎
Zhou, Xiaoyu, et al. “Gala3d: Towards text-to-3d complex scene generation via layout-guided generative gaussian splatting.” arXiv preprint arXiv:2402.07207 (2024). ↩︎ ↩︎ ↩︎
Poole, Ben, et al. “Dreamfusion: Text-to-3d using 2d diffusion.” arXiv preprint arXiv:2209.14988 (2022). ↩︎ ↩︎ ↩︎
Wang, Zhengyi, et al. “Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation.” Advances in neural information processing systems 36 (2023): 8406-8441. ↩︎ ↩︎ ↩︎
Chung, Jaeyoung, et al. “Luciddreamer: Domain-free generation of 3d gaussian splatting scenes.” arXiv preprint arXiv:2311.13384 (2023). ↩︎ ↩︎ ↩︎
Zhang, Lvmin, and Maneesh Agrawala. “Transparent image layer diffusion using latent transparency.” arXiv preprint arXiv:2402.17113 (2024). ↩︎ ↩︎