Video Gen Post-Training 研究分析 Video Gen Post-Training 研究分析 按照 Goal-driven research 方法论构建 Literature Tree 和 Challenge-Insight Tree,并识别研究空间。 一、Literature Tree(Novelty Tree) General Goal 让视频生成模型生成符合物理规律、用户偏好、语义准确、时空一致的高质量视频(Video Ge 2026-03-20 博士科研 #生成模型 #Diffusion #Transformer #Video Generation #Post-Training
Video Gen Post-Training 选题分析 Video Gen Post-Training 选题分析 按照研究方法论中的选题步骤:精确化 failure case → 判断 well-established solution 归属(4种情况)→ 确定技术挑战 → 选题决策。 选题判断框架(来自方法论) 情况 描述 建议 情况1 相同I/O任务,已有不错解决方案,只是有些地方还不够好 必须换题 情况2 I/O变化/多个不同 2026-03-20 博士科研 #生成模型 #Diffusion #Transformer #Video Generation #Post-Training
Driving with DINO:用视觉表征破解 Sim2Real 的一致性—真实性困境 论文主页:DwD Project Page 自动驾驶的闭环验证(closed-loop evaluation)一直是一个令人头疼的问题:在真实道路上测试代价高昂,危险案例(corner cases)又极难复现;而仿真器虽然提供了近乎无限的可扩展性,却因视觉保真度不足而与现实世界存在显著的域差距(domain gap)。如何弥合这道鸿沟,一直是自动驾驶数据工程的核心命题之一。 这篇博客介绍我们的 2026-03-09 科研论文 #自动驾驶 #生成模型 #Diffusion #Sim2Real #DINO
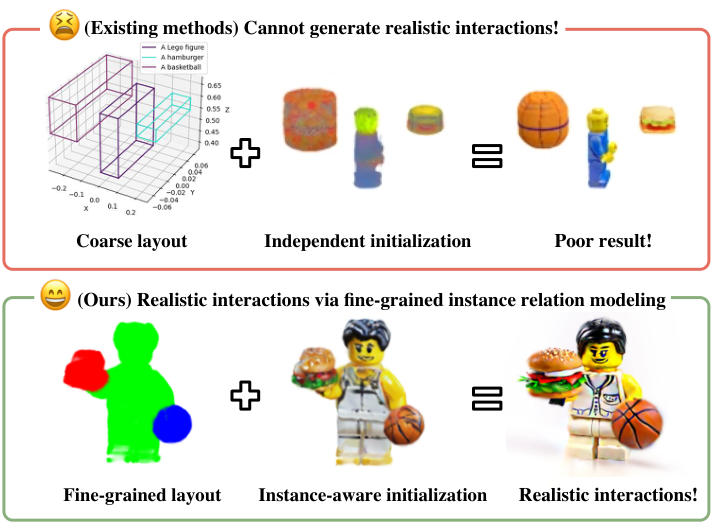
DreamFragment——3D-Instance aware的多物体 3D 场景生成 论文主页:DreamFragment Project Page 这是我研一期间在实验室做的工作 DreamFragment,在这篇博客中,我先尽量用介绍paper的视角介绍一下我这篇工作都干了什么。而下一篇博客我将和大家介绍一下这篇工作幕后的design space和想法,我认为可能更加有趣和给人启发。 3D多物体生成的key challenge 是:如何从文字描述中生成多个物体相互交互的复杂 2026-03-03 科研论文 #生成模型 #Diffusion #3D Generation #Gaussian Splatting #Text-to-3D #多物体场景
MDMPro:smpl motion2motion diffusion model 这是本科期间做的一个科研项目,要解决的问题是:在乒乓球对打场景下,给定对手的 SMPL 动作序列,如何预测并生成己方合理的动作响应。这种数据驱动类的work包含了数字人动捕的几个核心pipe——数据从哪里来、动作序列用什么表示、以及如何在条件生成中balance好语义准确性与多样性之间的张力。 2026-03-03 本科科研&工程 #生成模型 #Diffusion #Transformer #SMPL #姿态估计 #数字人
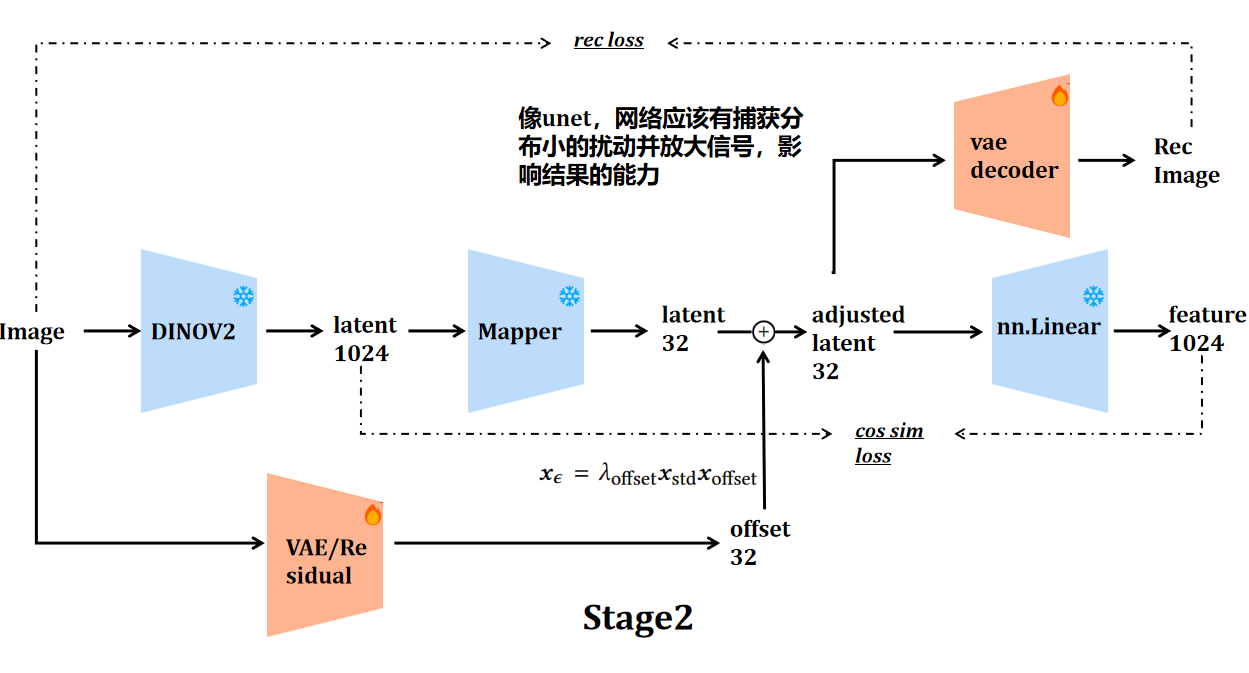
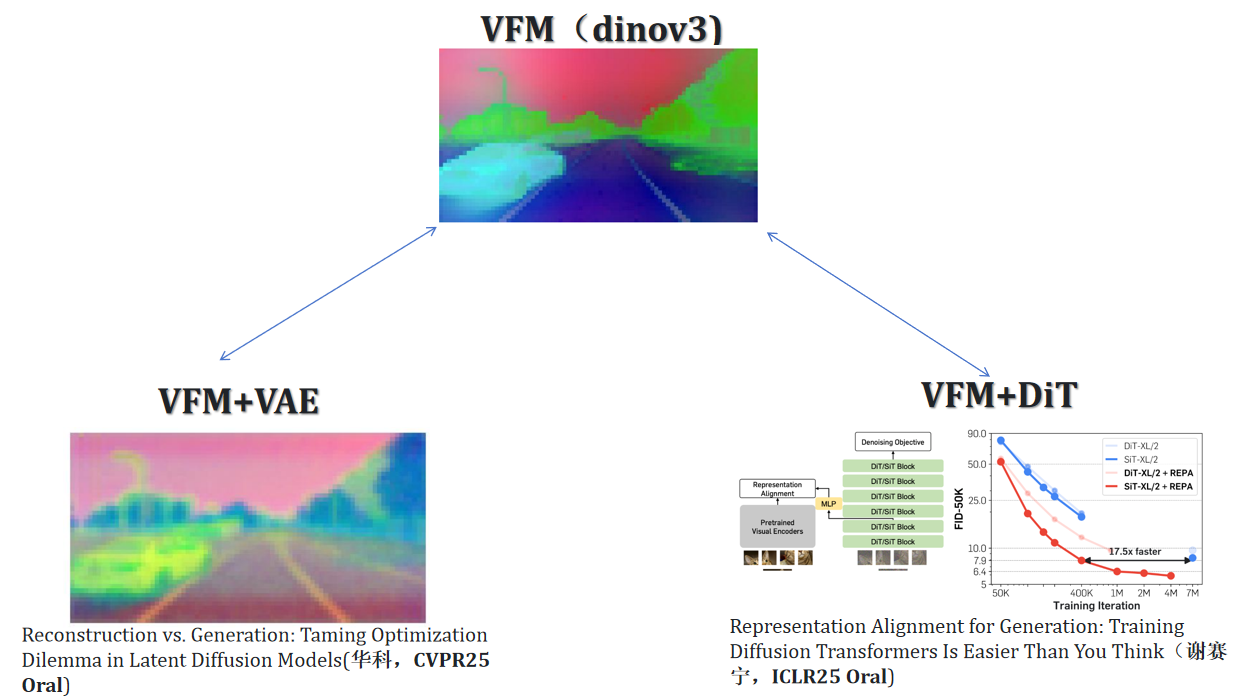
视觉表征漫谈2——VFM Tokenizer Design Space for Image Generation 上一次我们聊到了 VAVAE[1] 和 RAE[2] 类工作的困境,以及可能的解法。 这种解法可能是 DINOv4 探索的方案——一个在训练 VFM 的时候就能够良好保持住结构等信息的、模型参数量大的、数据更 diverse 的(比如见过很多字,这样高频信息的 gap 似乎有机会弥补),这样训练出来的 tokenizer 既保持了语义,又具备了很好的重建能力,但似乎是很久之后才会做到的事情。 有 2026-03-02 科研随笔 #生成模型 #Diffusion #视觉表征 #VAE
视觉表征漫谈1——从 VAVAE 到 RAE 表征和 VAE、Diffusion 的关系 事情的一开始要从 VAVAE[1] 和 REPA[2] 说起。 视觉表征(Visual Foundation Model,以下统一简写成 VFM),诸如 DINOv2[3]、DINOv3[4]、MAE[5],让神经网络在高维的隐空间(Latent Space)中学会了理解现实世界的深层物理与语义逻辑,继而可以使用这个通用的隐空间表征作为各种复杂下游视觉 2026-02-28 科研随笔 #生成模型 #Diffusion #视觉表征 #VAE
在公司集群上用 SLURM 跑多机多卡训练 相信大家一开始最头疼的任务之一,就是把一个已经支持分布式训练的模型跑到多台机器上。理论上听起来很简单——代码已经写好了,只需要run就行。但真正上手之后才发现,集群环境、网络配置、进程同步……每一个环节都有坑。遂出现这篇博客记录一下完整的流程。 为什么要用 SLURM? 公司的 GPU 集群统一由 SLURM(Simple Linux Utility for Resource Managemen 2025-10-09 工程实践 #SLURM #分布式训练 #HPC #PyTorch